Neural Image Representations
for Multi-Image Fusion and Layer Separation
Abstract
We propose a framework for aligning and fusing multiple images into a single view using neural image representations (NIRs), also known as implicit or coordinate-based neural representations. Our framework targets burst images that exhibit camera ego motion and potential changes in the scene. We describe different strategies for alignment depending on the nature of the scene motion—namely, perspective planar (i.e., homography), optical flow with minimal scene change, and optical flow with notable occlusion and disocclusion. With the neural image representation, our framework effectively combines multiple inputs into a single canonical view without the need for selecting one of the images as a reference frame. We demonstrate how to use this multi-frame fusion framework for various layer separation tasks.
Overview - Neural Image Representations (NIRs) for Multi-Image Fusion
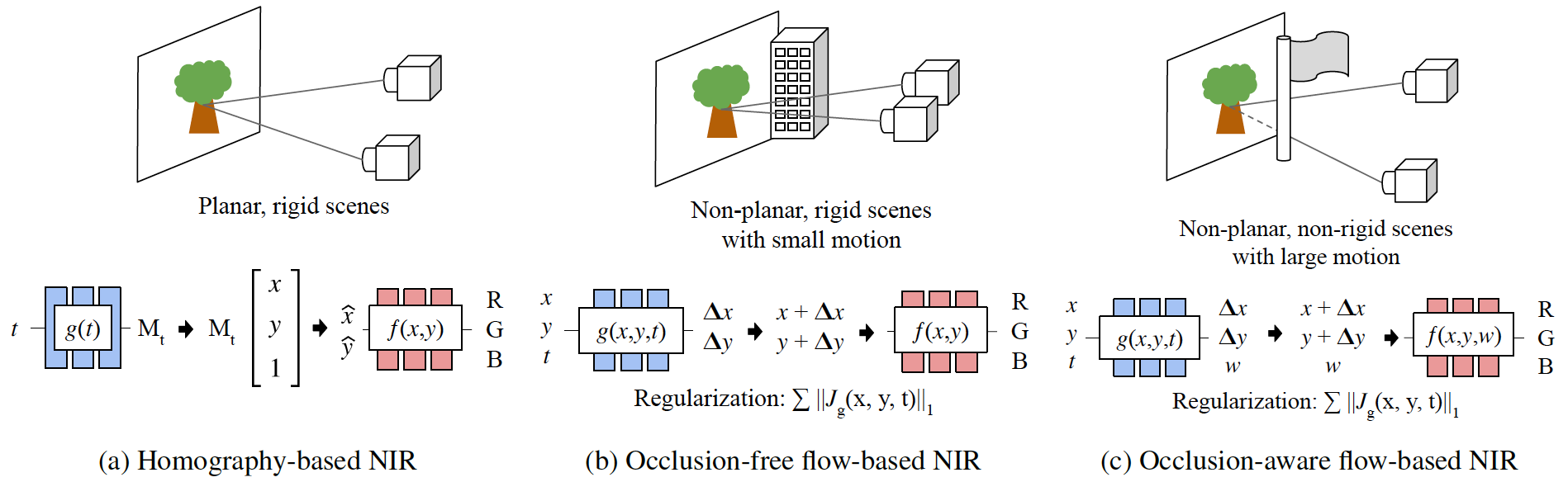
Figure 1. Illustration of our neural image representations (NIRs). Assuming that the MLP f learns a canonical view where all burst images are fused, we render each image by projecting the canonical view to the frame-specific view, which is achieved by transforming the input coordinates fed into the f. We estimate the transform using another MLP g. According to different assumptions of the world, we formulate our framework differently; we formulate the transform of coordinates using (a) homography, (b) optical flow without occlusion/disocclusion, and (c) optical flow with occlusion/disocclusion.
Visualization of Canonical View

Figure 2. Visualization of learned canonical view. We capture 9 consecutive images (left), and fit a homography-based neural representation to them. As can be seen, our method automatically stitches all the images in the canonical view (right) learned in the neural representation.
Overview - Multi-Image Layer Separation
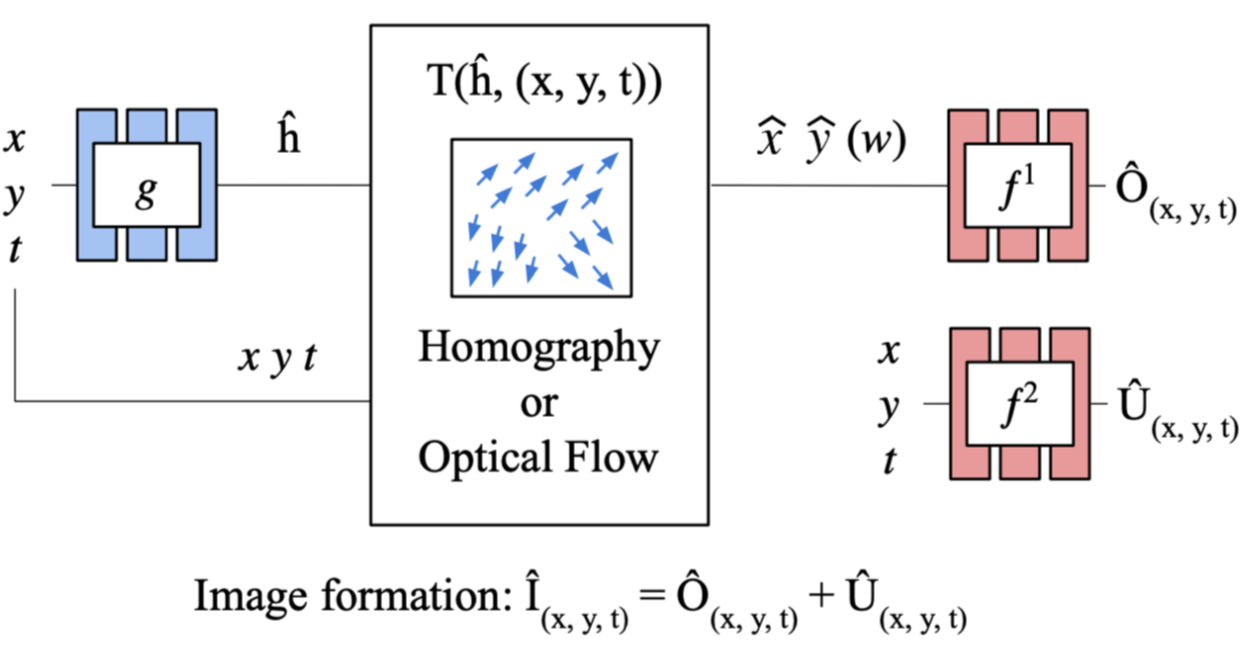
Figure 3. Overview of our two-stream NIRs for multi-image layer separation. The goal of our method is to separate the underlying scene and interference moving differently in images into two layers stored in a different NIR. To this end, we simultaneously train two NIRs. f1 is parameterized by our homography or flow-based NIRs so as to learn the underlying scene moving according to the explicit motion model. In contrast, the interference layer that is difficult to be modelled by the motion model is stored in f2. The generic form of image formation is a linear combination of both networks, but varies according to tasks. We also use a few regularizations for optimization, which are described in detail in the paper.
Application 1: Reflection Removal
| Input | Li et al., 2013 | Double DIP | Liu et al., 2020 | Ours |
|---|












Figure 4. Comparison of refleciton removal methods on real images. We used the baseline results reproduced by this, where video results are not available.
Application 2: Fence Removal
| Input | Liu et al., 2020 | Ours |
|---|


Figure 5. Comparison of fence removal methods on real images. We used the baseline results reproduced by this, where video results are not available. Note that the gray pixels in the fence layer of Liu et al. indicate empty, which is same as the black pixels in our result.
Application 3: Rain Removal
| Input | FastDeRain | Ours |
|---|
Figure 6. Comparison of rain removal methods on real images. All results are visualized in videos.
Application 4: Moiré Removal
| Input | AFN | C3Net | Double DIP | Ours |
|---|
Figure 7. Comparison of moiré removal methods on real images. All results are in videos.
Publications
- Neural Image Representations for Multi-Image Fusion and Layer Separation
Seonghyeon Nam, Marcus A. Brubaker, Michael S. Brown
Proc. European Conference on Computer Vision (ECCV) 2022